First, I’d like to welcome the new readers who found wanderingstan this weekend via the posts on TUAW, Gizmodo, and others!
For those of you just joining the story:  Last Thursday I posted a picture taken by Gwen Bell of her house-mates baked MacBook. As soon as Paul showed the photo I knew it had potential to go viral.
Last Thursday I posted a picture taken by Gwen Bell of her house-mates baked MacBook. As soon as Paul showed the photo I knew it had potential to go viral.
And so it did. The TUAW version of the story was Dugg (1828 so far), and I’ve had almost 15000 reads of that post.

This got me thinking: The web is beginning to operate very much the way our brain does. This is especially visible in the case of Digg.
You see, every neuron has a firing threshold. It has inputs from many other neurons, and when enough of those incoming neurons fire, the cumulative effect may be enough to cause it to fire.
Each digg story operates the same way. Each digg is a input activation for the story. When enough activation occurs within a short time period, the firing threshold is crossed: the story moves to the front page. (Note that the exact value of this threshold is a secret which Kevin Rose isn’t telling!) This “front page firing” causes activation of millions of readers.
Here’s a typical response chart for a neuron, and the physical structures responsible.
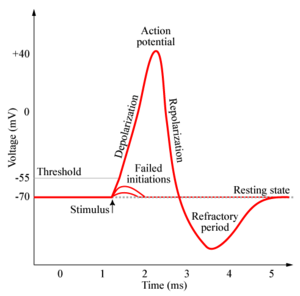
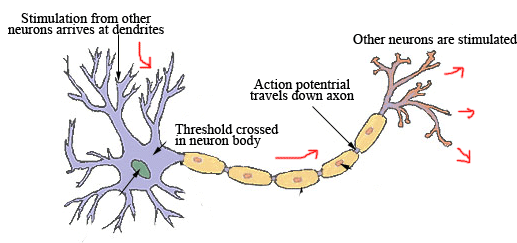
So what would this look like in Digg/Web-land? Here’s my take:
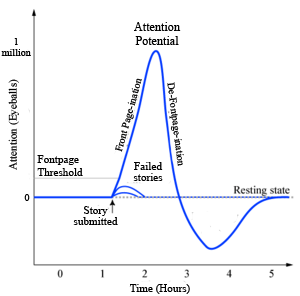

To stretch this analog further: Some of those readers will love the story so much that they then blob about it. In other words, the reader’s Personal Blogging Threshold™ was crossed, just like the firing threshold of the neuron. I suppose you could say twitter is the correct outlet for people with low PBT’s. 🙂
And how else can I end a post like this than with a “Digg This” button? Here you go!